
今回はDFLの弱点とFACEjAPPの開発を始めた経緯についてお話したいと思います。はじめに申し上げておくとFACEjAPPではDFLのtrainを使わせてもらっているためiperov氏(DFLの開発者)には頭があがりません。この記事を書くにあたっても先に感謝を述べさせていただきます。
DFLの学習はディープフェイクにおいて現時点で最高ですが、私は他のプロセスは最適ではないと思っています。その中でも二つ大きな弱点があります。これからDFLの課題とFACEjAPPでどのように解決したかについて解説していきたいと思います。うまく作れるようになるためにも弱点を把握することは大切だと思います。
目次
- DFLの歴史
- DFLは一発で作成できない
– DFLのプロセスとFACEjAPPのプロセスの違い
– EXTRACTの改善
– Datasetについて
– TRAINについて - DFLの輪郭内変換と前髪、二重眉問題
– 輪郭内変換の問題
– 前髪、二重眉問題 - まとめ
DFLの歴史
元々、DFLの開発者のiperov氏はdeepfakes/faceswap(以下FS)というコミュニティにいましたが、そりが合わずDeepFaceLabとしてFSからフォークしました。当時のFSはマスクの精度が低く、完成品のクオリティも微妙でした。そんな中、マスク学習、Segmentマスク、モデルの改良、超解像等をどんどん実装していき、FSよりもうまく作れるというDFLの評判はたちまち広がりDF界隈を席巻しました。FSは複数人で開発していたので保守的でスピード感に欠けたのに対して、良くも悪くも専制的で革新的なiperov氏の課題解決へのアプローチ、実装のスピードは本当にすごかったです。天才だと思います。関係ないけどtensorflowの開発チームに喧嘩売っちゃうところとかも大好きですw(開発者には敬意を払いましょう)
…DF史の話はいくらでもできますがこの辺にして、じゃあDFLで満足いくものができたの?と言われると私は満足できませんでした。
DFLは一発で作成できない
FACEjAPPが一番こだわっているのが一発で作成という部分です。DFLはExtractの精度が低いのでプロセスが終わるのを待って確認してから学習しなければなりません。
df作成の流れはおおまかに
- Extract(動画から顔を抽出)
- Train(顔の学習)
- Convert(顔を変換)
の3つです。
加えてDFLでは、プロセスの前後に動画から連番画像、連番画像から動画という作業があったりします。(※FACEjAPPとFSは動画から直接変換できます。PNGで画像にばらしてしまうとえげつない容量になってしまいますし、JPEGだと書き出すごとに画像は劣化してしまいます。)
DFLのプロセスとFACEjAPPのプロセスの違い
DFLのプロセス
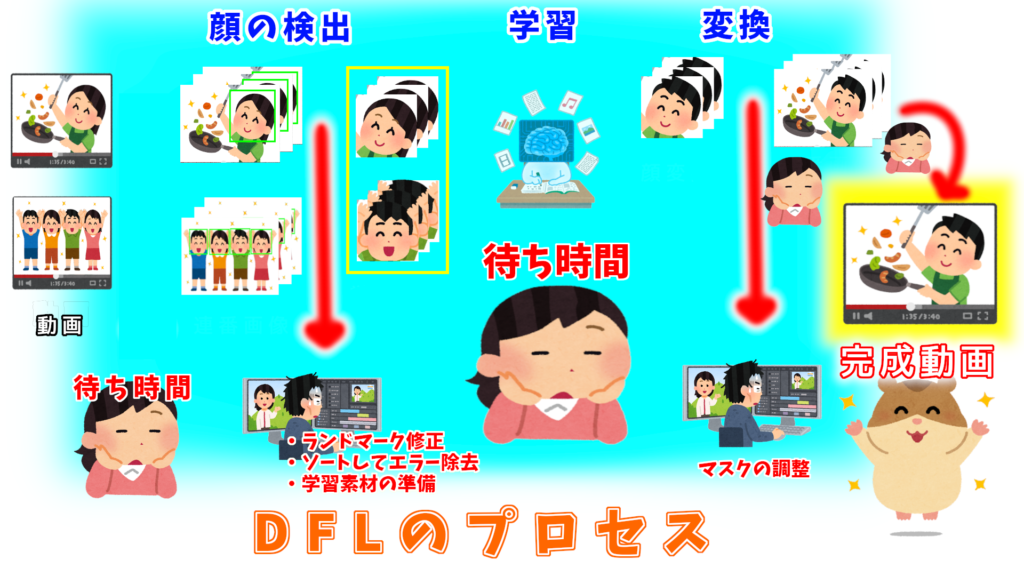
動画から画像になるのを待って、Extractが終わるのを待って、ソートしてから検出ミスを修正して、顔セットを用意して、Trainが終わるのを待って、gan追加してTrainが終わるのを待って…とやっていくと非常に時間がかかります。
FACEjAPPのプロセス

Extractの精度を向上させて、ターゲットを一人に絞り、顔セットを最適化するまでのプロセスを確立できれば完成まで自動化できます。一番最初に取り組んだのがExtractの改善でした。
EXTRACTの改善
Extractはめちゃくちゃ改善の余地がありました。上げていくときりがないですがFACEjAPPのExtractは難しいシーンでも抽出できるように多くが最適化されています。Extractにかかる時間もDFLより10倍速いです。
RetinaFace
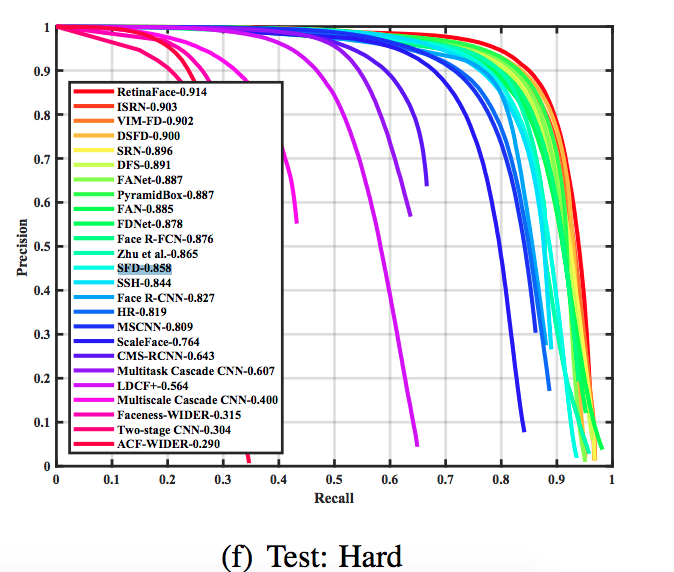
私は最初に質の高いdetector(顔の検出器)を探しました。detectorというのはここでは一枚の画像から顔のある範囲を見つけるタスクです。いろいろ試した結果RetinaFaceというdetectorを使うことにしました。元々InsightFaceという顔認識のプロジェクトで知りましたが、このRetinaFaceという顔の検出器の精度はめちゃくちゃ高く、今でも顔の検出が必要なCV系の論文でよく出くわします。余談ですが、InsightFaceの顔認識の精度も高いので顔セットを作成する際にそちらも利用させていただいています。実は、このRetinaFace優秀なのでDFLでもユーザーによって提案されたことがありました。結果そのユーザーのコードがtensorflowではなくPytorchでの実装だったので却下されています。あの時提案を受け入れていたらDFLのユーザーたちは時間をもっと節約できていたと思います。S3FDは何回も探索するので検出時間もかなり遅いです。
また、detectorは顔のあるエリアを見つけるものですが、顔のあるエリアからランドマークとなるポイントを見つけるタスクをface alignmentといいます。FACEjAPPではこの68個のランドマークを見つけるAlignerもより精度の高いものを採用しています。
DFLの回転オプションについて
rotateは上向きで顔が見つかなければ、右向き、右向きで見つからなければ、下向きというように顔が見つかるまで回転していくオプションです。

一見検知できているのでよさそうに見えますが、顔の向きが上か横か中途半端なシーンで、上向きで見つかるときと、右向きで見つかるときでランドマークにずれが生じてしまう欠点があり、動画にすると不安定なシーンができてしまいます。

私は改造を始める前は顔が横を向いている場合、動画を90度(270度)回転して顔の向きが上になるように再エンコードしてから作成していました。基準を決めてあげれば上記の問題を解決できるからです。うちのソフトを利用している方はわかると思いますがこれが顔の向きが変わるときにシーンを分ける理由です。
DSTを一人に絞る
自動化するためには、dstに何人か人が写っている場合一人に絞る必要があります。私たちがよく作るであろう動画は顔が乱れるので正直これが一番難しいですが、FACEjAPPではランドマークの追跡アルゴリズムと先ほどの顔認識を使って、余程複雑なシーンでない限りは自動で一人に絞るようになっています。
その他
他にも補完やスムージングを使って動画の連続性に耐えられるようにランドマークを調整したり、alignerに渡す時に顔がなるべく正面になるようにしてコンバートのときにブレないようにできることは全てやってます。
Dataset
学習において学習素材の前処理は非常に重要なプロセスです。コレ知らない人多い印象です。詳しくは割愛しますがFACEjAPPではこのプロセスも自動で最適な学習セットになるようになっています。
Data Augmentation
学習素材に処理を加えて水増しすることをData Augmentation(データ拡張)といいますが、超解像もその中の一つです。
GPEN
GPENは超解像(高解像度化)においてとても優れています。
残念ながらGPENは商用不可だったのでアプリに組み込めませんでしたが、あくまで教育目的でGoogle Colabで使えるようにしたのでよかったら試してみてください。(DFLでも使えると思います。)
TRAINについて
FACEjAPPのTrainはDFLを利用しています。DFアーキとLIAEアーキがありますが、FACEjAPPのゴールの一つはなるべく多くのシーンで実用的なDFを作ることなのでLIAEアーキをメインに使っています。
DFアーキ
DFアーキの特徴はなんといっても正面がうまくいきやすいことです。特にtrueface powerを使うとSRCの特徴を最大限発揮できます。反面、構造上正面以外はうまくいきにくい、truefaceを使うとなじませるのが難しいというデメリットもあります。
LIAEアーキ
LIAEアーキの特徴は角度がついてもある程度耐えられるのでいろいろなシーンが作れます。また、変換したときに馴染ませやすいのもメリットです。しかし、DFアーキの方がSRCの特徴が出やすいですし、構造上truefaceも使えません。
それぞれ長所も短所もあるのでどちらがいいというのはないと思います。大事なのはそれぞれの特徴を知って最適なモデルを選択することです。ただDFアーキの横顔を見て揚げ足をとったり、LIAEアーキの正面だけを見てDFアーキの方が優れているとするのは違うと思います。
DFLの輪郭内変換と前髪、二重眉問題
ここまで主にExtractの問題を羅列してきましたが、DFLはConvertにも弱点があります。よく私にdstを聞いてくるDFLユーザーの方がいます(※お答えできないので本当にやめてください)がうちとDFLでは同じ変換にはなりません。そもそもうちとはdstを探す時に注意するポイントが異なります。
輪郭内変換の問題
DFLのマスクのデフォルトはDSTのマスクとSRCのマスクの共通部分です。ここでのマスクは変換される予測顔の範囲のことです。
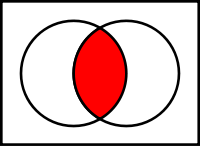
わかりにくいと思うので丸パンマン、カリーナンマン、四角パンマンに登場してもらって説明します。




輪郭内変換
極端に言えばDFLのデフォルトはこんな感じです。境界にややぼかしをかけてDSTになじませるのがセオリーです。一見この共通部分でのマスクは安定していてよさそうに見えますが、輪郭がDSTになってしまい全く似なくなってしまうという問題をかかえています。

理想はコレのはずです。とはいえ四角パンマンを丸パンマンにするのはバランスもある(引き延ばされる)ので難しいです。
解決策として輪郭の似たDSTを探すのはセオリーですが、そうそう輪郭が合う人は見つかりません。ただでさえ作れるシーンが限られているのに、輪郭や髪型で絞られてしまうとなかなか満足いく作品は作れなくなってしまいます。バランスは仕方ないにしてもSRCの輪郭を使う方法はないのでしょうか。
方策
私はDFに実力があるとするならこのSRCの輪郭の出し方の上手さのことだと思っています。
方策として第一に考えられるのは、変換範囲のマスクを広げる(dilate)方法です。バニラ(改造なし)でできますが、広げると変換した顔の周りの汚い背景が目立ったり、なじませようとしてブラーをかけるとdstが透けて見えてしまったりとデメリットもあります。(正面はうまくいきやすいです。)基本的には世に出回っているDFは先ほどの輪郭内変換のものか顔周りがボケているようなものになります。
第二に考えられるのは、一度そのまま(raw)出力し編集ソフトで仕上げる方法です。この方法を極めれば一番きれいにできますが、CMや映画ならわかりますが、たかだか一回のDFにそこまで時間もかけられないというのが現実ではないでしょうか。習得にも時間がかかります。
第三に考えられるのはコードを少し弄って、マスクを共通部分から和集合に替える方法です。
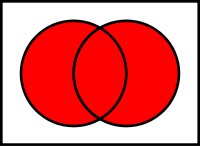

DSTにSRCの範囲が収まれば目立ちにくく、さらに正面なら顔周りの背景も学習してくれているのである程度なじみます。

問題はSRCの顔の範囲からはみ出たDSTの部分です。
うちの場合はこの三つ目の方法に、inpaintingの技術も使いながら、SRCの輪郭を出しつつ、つなぎの部分(背景とSRCの境目)が目立たなくなるように調整しています。これにより体や頭の形、バランスを優先してdstを選ぶことができます。
前髪、二重眉問題
先ほど申し上げた通り、DFLでは境界をぼかすのがセオリーです。ここでDFLは日本人向けにできていないため、前髪、二重眉問題(外国人は前髪のある女性が少ない)が発生します。前髪の境目でぼかされるためDSTの眉や鼻筋が見えてしまい違和感が出てしまうという問題です。ただ、これは前髪も学習するようにセグマスクを調整してあげればいいのかなと思います。
結び
いかがだったでしょうか?バニラのDFLには特定の条件でしかうまくいきにくいという問題があります。(DFLで正面を極めるのも全然ありだと思います。)しかしSRCの輪郭が出せれば選択肢はかなり広がります。ただしSRCの輪郭を出せても、バランスの相性もあるため、失敗するときは失敗します。私の場合、失敗してもどんどんチャレンジできる環境にあるため気軽に作成することができますが、DFLでは手間と時間がかかってしまいます。既存のアプリはうまくいく確率と作成の大変さが見合ってないと思います。
FakeAppというアプリから始めて、FS、DFLと試しましたがこれらの問題があるため私も最初はなかなか満足いく作品が作れませんでした。(ちなみにFACEjAPPの名前の由来は、fakeappとfaceswapのもじりです。当時日本人特有の前髪問題を解決したい気持ちが強かったのでJPOPのノリでJAPPになりました。)当時は、もっと簡単に作れるアプリがあればとか、上手に作っている人を見て有料でもいいので作り方を教えて欲しいなとか考えておりました。
そして問題を解決していき満足いくDFが作れるようになってくると、せっかくなら同じ悩みを持ってる人にも使って欲しいと思うようになりました。そんなこんなでサブスクのサービスを始めることにしました。(お金を頂くことに関しては心苦しいですが、自分だけで使うのとは違い、他人に使ってもらうようにするためには開発にも説明にもQ&Aにも何倍も時間がかかってしまうためご理解いただきたいです。その代わり全力でサポートさせて頂きます!)
FACEjAPPには私のノウハウが全て詰まっておりますので同じ悩みを抱えている方がいましたら是非試してみてください!